
[ad_1]
T'was the day earlier than genesis, when all was ready, geth was in sync, my beacon node paired. Firewalls configured, VLANs galore, hours of preparation meant nothing ignored.
Then all of sudden every little thing went awry, the SSD in my system determined to die. My configs had been gone, chain information was historical past, nothing to do however belief in subsequent day supply.
I discovered myself designing backups and redundancies. Difficult methods consumed my fantasies. Considering additional I got here to grasp: worrying about these sorts of failures was fairly unwise.
Occasions
The beacon chain has a number of mechanisms to incentivise validator behaviour, all of that are dependant on the present standing of the community, so it’s vital to contemplate these failure instances within the higher context of how different validators may fail when deciding what are, and what aren’t, worthwhile methods of securing your node(s).
As an lively validator, your steadiness both will increase or decreases, it by no means goes sideways*. Due to this fact a reasonably affordable method of maximising your income, is to minimise your downsides. There are 3 methods your steadiness will be lowered by the beacon chain:
- Penalties are issued when your validator misses one in every of their duties (e.g. as a result of they’re offline)
- Inactivity Leaks are handed out to validators that miss their duties whereas the community is failing to finalise (i.e. when your validator being offline is very correlated with different validators being offline)
- Slashings are given to validators who produce blocks or attestations which are contradictory and subsequently could possibly be utilized in an assault
* On common, a validator’s steadiness could keep the identical, however for any given responsibility, they’re both rewarded or punished.
Correlation
The impact of a single validator being offline or performing slashable behaviour is small by way of the general well being of the beacon chain. It’s subsequently not punished closely. In distinction, if many validators are offline, the steadiness of offline validators can lower way more quickly.
Equally, if many validators carry out slashable actions on the similar time, from the beacon chain’s perspective, that is indistinguishable from an assault. It’s subsequently handled as such, and 100% of the offending validators’ stake is burned.
Due to these “anti-correlation” incentives, validators ought to fear extra about failures that may have an effect on others on the similar time fairly than remoted, particular person points.
Causes and their chance.
So let’s suppose by some failure instances and study them by the lens of what number of others could be affected on the similar time, and the way badly your validators could be punished.
I disagree with @econoar here that these are worst case points. These are extra reasonable stage points. Residence UPS and Twin WAN deal with failures aren’t correlated with different customers and so must be far down your checklist of issues.
🌍 Web/energy failure
In case you are validating from house, then it is extremely seemingly you will encounter one in every of these failures in some unspecified time in the future sooner or later. Residential web and energy connections shouldn’t have assured uptime. Nevertheless, when the web does go down, or your energy is out, the outage is normally restricted to your space and even then just for a couple of hours.
Except you have got very spotty web/energy, it may not be worthwhile paying for fall-over connections. You will obtain a couple of hours of penalties, however as the remainder of the community is operating usually, your penalties will probably be roughly equal to what your rewards would have been over the identical interval. In different phrases, a okay hour-long failure units your validator’s steadiness again to roughly the place it was okay hours earlier than the failure, and in okay further hours your validator’s steadiness will probably be again to its pre-failure quantity.
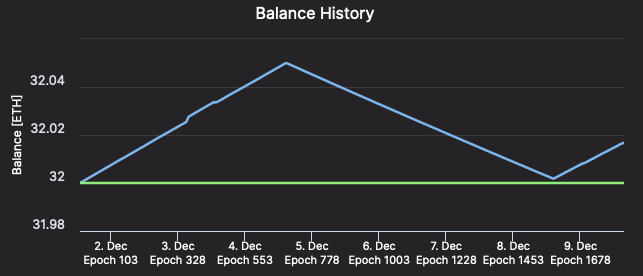
[Validator #12661 regaining ETH as quickly as it was lost – Beaconcha.in
🛠 Hardware failure
Like internet failure, hardware failure strikes randomly, and when it does, your node might be down for a few days. It is valuable to consider the expected rewards over the lifetime of the validator versus the cost of redundant hardware. Is the expected value of the failure (the offline penalties times the chance of it happening) greater than the cost of the redundant hardware?
Personally, the chance of failure is low enough and the cost of fully redundant hardware high enough, that it almost certainly isn’t worth it. But then again, I am not a whale 🐳 ; as with any failure scenario, you need to evaluate how this applies to your particular situation.
☁️ Cloud services failure
Maybe, to avoid the risks of hardware or internet failure altogether, you decide to go with a cloud provider. With a cloud provider, you have introduced the risk of correlated failures. The question that matters is, how many other validators are using the same cloud provider as you?
A week before genesis, Amazon AWS had a prolonged outage which affected a large portion of the web. If something similar were to happen now, enough validators would go offline at the same time that the inactivity penalties would kick in.
Even worse, if a cloud provider were to duplicate the VM running your node and accidentally leave the old and the new node running at the same time, you could be slashed (the penalties incurred would be especially bad if this accidental duplication affected many other nodes too).
If you are insistent on relying on a cloud provider, consider switching to a smaller provider. It may end up saving you a lot of ETH.
🥩 Staking Services
There are several staking services on mainnet today with varying degrees of decentralisation, but they all contain an increased risk of correlated failures if you trust them with your ETH. These services are necessary components of the eth2 ecosystem, especially for those with less than 32 ETH or without the technical know-how to stake, but they are architected by humans and therefore imperfect.
If staking pools eventually grow to be as large as eth1 mining pools, then it is conceivable that a bug could cause mass slashings or inactivity penalties for their members.
🔗 Infura Failure
Last month Infura went down for 6 hours causing outages across the Ethereum ecosystem; it is easy to see how this is likely to result in correlated failures for eth2 validators.
In addition, 3rd party eth1 API providers necessarily rate-limit calls to their service: In the past this has caused validators to be unable to produce valid blocks (on the Medalla testnet).
The best solution is to run your own eth1 node: you won’t encounter rate-limiting, it will reduce the likelihood of your failures being correlated, and it will improve the decentralisation of the network as a whole.
Eth2 clients have also started adding the possibility of specifying multiple eth1 nodes. This makes it easy to switch to a backup endpoint, in the event your primary endpoint fails (Lighthouse: –eth1-endpoints, Prysm: PR#8062, Nimbus & Teku will likely add support somewhere in the future).
I highly recommend adding backup API options as cheap/free insurance (EthereumNodes.com shows the free and paid API endpoints and their current status). This is useful whether you are running your own eth1 node or not.
🦏 Failure of a particular eth2 client
Despite all the code review, audits, and rockstar work, all of the eth2 clients have bugs hiding somewhere. Most of them are minor and will be caught before they present a major problem in production, but there is always the chance that the client you choose will go offline or cause you to be slashed. If this were to happen, you would not want to be running a client with > 1/3 of the nodes on the network.
You must strike a tradeoff between what you deem to be the best client vs how popular that client is. Consider reading through the documentation of another client so that if something happens to your node, you know what to expect in terms of installing and configuring a different client.
If you have lots of ETH at stake, it is probably worth running multiple clients each with some of your ETH to avoid putting all your eggs in one basket. Otherwise, Vouch is an interesting offering for multi-node staking infrastructure, and Secret Shared Validators are seeing rapid development.
🦢 Black swans
There are of course many unlikely, unpredictable, yet dangerous scenarios that will always present a risk. Scenarios that lie outside the obvious decisions about your staking set-up. Examples such as Spectre and Meltdown at the hardware level, or kernel bugs such as BleedingTooth hint at some of the hazards that exist across the entire hardware stack. By definition, it is not possible to entirely predict and avoid these problems, instead you generally must react after the fact.
What to worry about
Ultimately this comes down to calculating the expected value E(X) of a given failure: how likely an event is to happen, and what the penalties would be if it did. It is vital to consider these failures in the context of the rest of the eth2 network since the correlation greatly affects the penalties at hand. Comparing the expected cost of a failure to the cost of mitigating it will give you the rational answer as to whether it is worth getting in front of.

No one knows all the ways a node can fail, nor how likely each failure is, but by making individual estimates of the chances of each failure type and mitigating the biggest risks, the “wisdom of the crowd” will prevail and on average the network as a whole will make a good estimate. Furthermore, because of the different risks each validator faces, and the differing estimates of those risks, the failures you did not account for will be caught by others and therefore the degree of correlation will be reduced. Yay decentralisation!
📕 DON’T PANIC
Finally, if something does happen to your node, don’t panic! Even during inactivity leaks, penalties are small on short time scales. Take a few moments to think through what happened and why. Then make a plan of action to fix the problem. Then take a deep breath before you proceed. An extra 5 minutes of penalties is preferable to being slashed because you did something ill-advised in a rush.
Most of all: 🚨 Do not run 2 nodes with the same validator keys! 🚨
Thanks Danny Ryan, Joseph Schweitzer, and Sacha Yves Saint-Leger for review
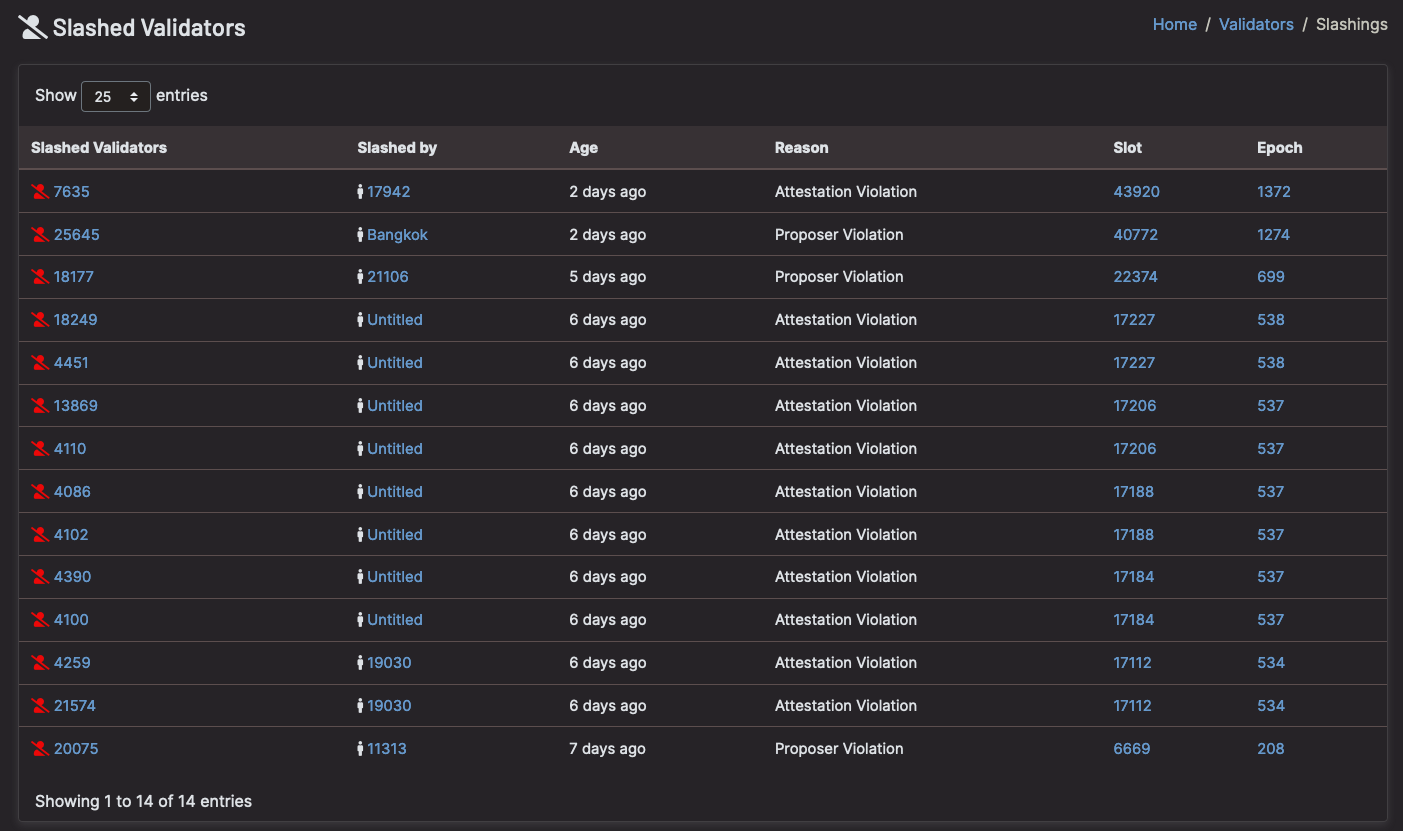
[Slashings because validators ran >1 node – Beaconcha.in]
[ad_2]
Source link